Building a Human-in-the-Loop Reddit Lead Engine with n8n, Claude, Local LLMs, and Slack

Reddit has a lot of really good content from students looking for better ways to study. It also has parents asking how to help their children prepare for tests, remember what they are learning, stay organized, or become more independent with schoolwork.
Those people are not cold leads. They are already writing about the exact problems CleverOwl is trying to solve.
I started CleverOwl because of my own children. I watched them struggle with studying and found that many of the more powerful tools were not especially child-friendly. They could do a lot, but they were not always easy for a student to use on their own. I wanted something simple enough for a child to use independently, while still giving them access to the kind of structure and personalization you would expect from a more advanced learning tool.
At first, I was manually reading Reddit posts. I had a list of communities where students and parents were talking about studying, school stress, test prep, motivation, and learning tools. I would browse those subreddits, open interesting posts, read the comments, and decide whether it made sense to respond.
That worked for a little while. Then it became unmanageable, so I built a system to do the discovery and triage for me.
I need to be really clear about this upfront: The goal was not to build an automated spam machine. The goal was to build a human-in-the-loop lead discovery system that could monitor the right communities, find high-intent conversations, explain why they might be relevant, and notify me when something was worth reviewing.
The stack looks like this:
- n8n for workflow orchestration
- Reddit JSON endpoints for post and comment data
- Postgres for queueing and state
- LocalLM with Gemma 4 for lead scoring
- Modash for LLM observability
- Slack for alerts and review
- Claude for building, modifying, and publishing the workflows
- Pulumi and Kubernetes for the local model infrastructure
The basic workflow
The workflow runs continuously throughout the day. It watches a curated list of roughly 20–30 subreddits that I selected manually by browsing Reddit, searching Google, and looking for places where students and parents were already having the kinds of conversations CleverOwl is relevant to.
That manual curation matters. The system is not trying to monitor all of Reddit. It is watching a focused set of communities where the signal is already relatively high.
When the workflow finds a new post, it uses Reddit’s JSON endpoints to fetch the post and its comments. It then queues the work in Postgres so the rest of the system can process it reliably.
At a high level, the indexing pipeline looks like this:

And the processing pipeline looks like this:

The system processes around 1,500 Reddit posts per day on average. That is exactly why the manual approach stopped working. Even if only a small percentage of posts are relevant, reading through that much content every day is not a reasonable use of time.
Scoring posts with a local LLM
The scoring step looks at the full context: title, body, subreddit, and comments. That context is important because keyword matching is not good enough for this problem. A lot of posts are adjacent to CleverOwl without being qualified leads.
For example, someone might be asking about meditation to manage ADHD so they can focus or study better. That is clearly related to studying, but it is not the kind of problem CleverOwl is built to solve.
The LLM is given a prompt that explains what a qualified lead looks like, with examples. It then evaluates the conversation and assigns a confidence score based on whether the post appears to match the kinds of students or parents CleverOwl can actually help.
The highest-signal posts are usually things like:
- a student asking how to study more effectively
- someone struggling to prepare for an upcoming test
- a student who keeps forgetting what they read
- a parent asking how to help their child study more independently
- someone looking for a better way to turn notes or study materials into something useful
Here is a snippet from the scoring prompt, as an example of how we increase and decrease scoring confidence:
LEAD CONFIDENCE SCORING (use this to set confidence)
Start at 0.50, then adjust:
+0.20 if they explicitly mention exam/test coming up or being behind
+0.15 if they mention too many notes / disorganized notes / "don't know how to study"
+0.15 if they mention multiple formats (slides + PDF + handwritten + photos)
+0.10 if they ask for tools/apps/workflows
+0.10 if comments show others have same problem or express interest
+0.05 if comments indicate this is a common struggle
-0.30 if it's mainly language learning
-0.30 if it's mainly math
-0.20 if it's not really asking for help (just a story/meme)
-0.10 if comments already solved their problem
Clamp final confidence to 0.00-1.00.I currently send posts to Slack when they clear the threshold. In practice, the system finds around 20 posts per day above 75% confidence. Fewer than five per day are usually above 85%, and those are the ones I care about most.
Some days are better than others. That is expected. Reddit activity is uneven, and not every day produces a perfect high-intent conversation. But the system does a good job reducing a large, noisy stream of posts into a small number of conversations worth reading.
Why I moved from hosted models to local models
I originally started by using hosted LLMs through OpenRouter. That worked, but it became expensive quickly.
The issue was volume. This system is not scoring one or two posts. It is constantly pulling posts and comments from a curated list of communities, and each scoring request can include a meaningful amount of text. Once you start evaluating Reddit threads continuously, token usage adds up quickly. That pushed me toward local models.
I tried a few different models and found Gemma 4 to be very good for this kind of classification task. The job here is not long-form creative writing. It is structured judgment: given a post, comments, and examples of what a qualified CleverOwl lead looks like, decide whether this is actually a fit.
Running the model locally gave me much better economics, but it introduced a new problem: observability.
I wanted to understand:
- how many LLM requests were in flight
- how many tokens were going in and out
- how much traffic each model was handling
- whether the local model was keeping up
- what historical usage looked like across the system
That led me to build Modash.
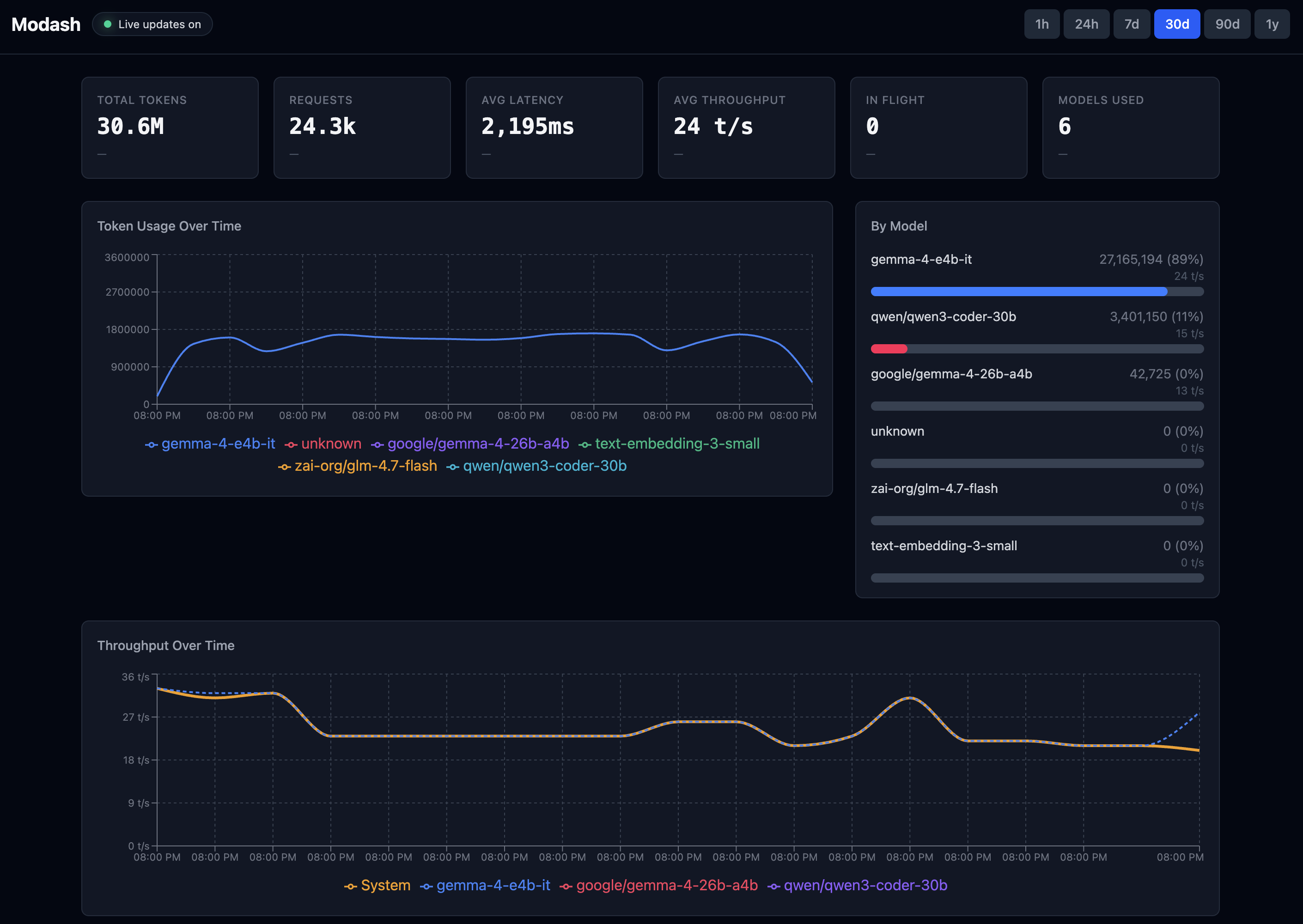
Modash is an LLM proxy that sits between n8n and LM Studio. n8n sends requests to Modash, Modash forwards them to the local model, and I get visibility into token usage, request volume, throughput, latency, and model-level activity.
Check it out at https://github.com/bryanmig/modash
In one snapshot, Modash showed more than 30 million tokens processed across more than 24,000 LLM requests. Those numbers do not map perfectly to the daily post count because the dashboard reflects a newer slice of system activity, but they make the point: hosted model costs can become meaningful very quickly when you are scoring a large volume of content all day long.
Local models are not magically free. You still need to care about throughput, latency, resource usage, and whether the model is good enough for the job. But for this use case, local inference made a lot of sense. While the rest of this pipeline is running in a MicroK8s cluster, LocalLM is running on a dedicated MacBook Pro with an M4 Max and 128GB RAM.
Claude as the automation builder
One of the more interesting parts of this project is that Claude was involved in building the system itself.
Claude helped create the n8n automation, wire up the database interactions, stand up LocalLM with Gemma inside my Kubernetes cluster, and generate the Pulumi code for managing and deploying the infrastructure.
The n8n workflow itself is a generated JSON blob. Claude has API access to n8n, so it can read the current workflow state, modify it locally, and publish the updated version back through the n8n API. The workflow JSON is stored in the project and committed to GitHub alongside the Pulumi infrastructure code. That changed how I think about n8n.
The visual builder is useful, but the API makes it possible to treat workflows as versioned, reviewable, deployable artifacts. The workflow is not just something I clicked together in a UI. It is part of the codebase. It can be generated, reviewed, changed, committed, and redeployed.
That is a big shift in how no-code and low-code tools can fit into a technical system.
Slack as the human review surface
When a post clears the threshold, the workflow sends a Slack alert.
The alert includes the information I need to quickly decide whether the post is worth opening:
- title
- subreddit
- author
- score
- comment count
- Reddit link
- why the model thinks it is a good lead
- suggested response direction
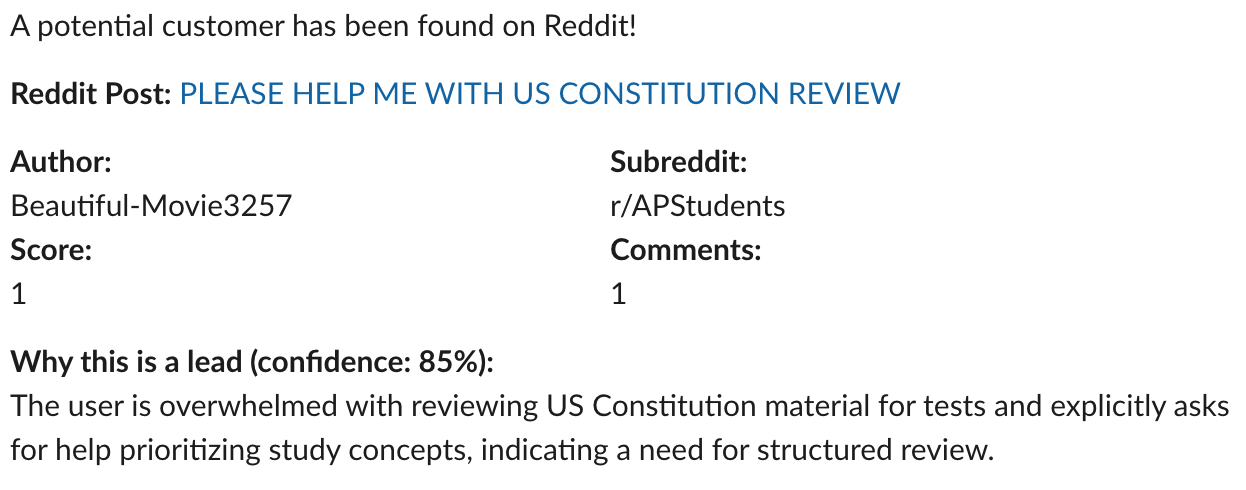
The explanation is important. A raw score is not enough. I want to know why the model thinks the post is relevant so I can quickly judge whether it actually matches the kind of person CleverOwl can help.
The notifications go to both my laptop and phone, so I can react quickly when something high-signal appears. The workflow also makes it easy to respond from Slack, which keeps the loop fast. In practice, though, I usually still open the Reddit thread before responding.
That is intentional: A post can look like a perfect lead at first, but the comments may change the context. Maybe the discussion moved in a different direction. Maybe someone already gave the right answer. Maybe replying with a product suggestion would feel out of place. I do not want to show up sounding like a bot, and I definitely do not want this system to become an automated outreach machine.
The automation can suggest how I might want to respond, but there is a fine line between AI-assisted context and AI-generated spam. I always write the actual response myself and make sure it is aligned with the discussion.
The goal is to automate discovery, not engagement.
Results so far
The system processes around 1,500 Reddit posts per day on average.
From that, roughly 20 posts per day clear the 75% threshold and get sent to Slack. Fewer than five per day usually score above 85%, and those are the ones I care about most.
Like any funnel, the number of people who actually sign up is much smaller than the number of qualified leads. A high-confidence Reddit post is still just a conversation, not a guaranteed customer.
But the system is working in the way I hoped it would. There is a steady, slow flow of people trying CleverOwl every week, and I am no longer manually scanning dozens of communities to find those opportunities.
Just as importantly, the system keeps me close to the kinds of problems students and parents are already describing in their own words.
I do not want to overstate that part. This has not radically changed the product roadmap. Its main value is much more practical: it helps me find relevant conversations quickly, understand whether there is real intent, and respond when I can be genuinely helpful.
What I think is interesting about this
There are three lessons I keep coming back to.
First, n8n plus AI is a very practical automation stack. It is not just useful for simple internal workflows. With the right supporting pieces, it can orchestrate a real system: external data sources, queueing, LLM scoring, notifications, and human review.
Second, no-code workflows become much more powerful when you treat them like code. The n8n workflow is generated JSON, stored in GitHub, and deployed through the API. The infrastructure around it is managed with Pulumi and Kubernetes. That makes the system much easier to reason about and maintain than a one-off workflow living only in a visual editor. Plus, when things go wrong, Claude and Codex can just kubectl their way around to figure out why - and then fix it faster than I could.
Third, AI is most useful here when it scales judgment rather than replacing it. The LLM is not replying to Reddit posts for me. It is helping me find the posts worth reading. It reduces the search space from 1,500 posts per day to a handful of high-signal conversations.
That is the part that feels right to me. I do not want a bot pretending to be human. I want a system that helps me notice the people who are already asking for help, so that when I do respond, I can do it thoughtfully.